
On the night of April 16, I opened the Claude client and found that it had quietly updated to version 4.7.
I took a screenshot to send to a friend, saying I would write a review, then remembered to check the official announcement.
The announcement link opened with a stable title:
Claude Opus 4.7, Our Most Powerful Opus Model Yet
However, the subtitle contained a line that stunned me for a second:
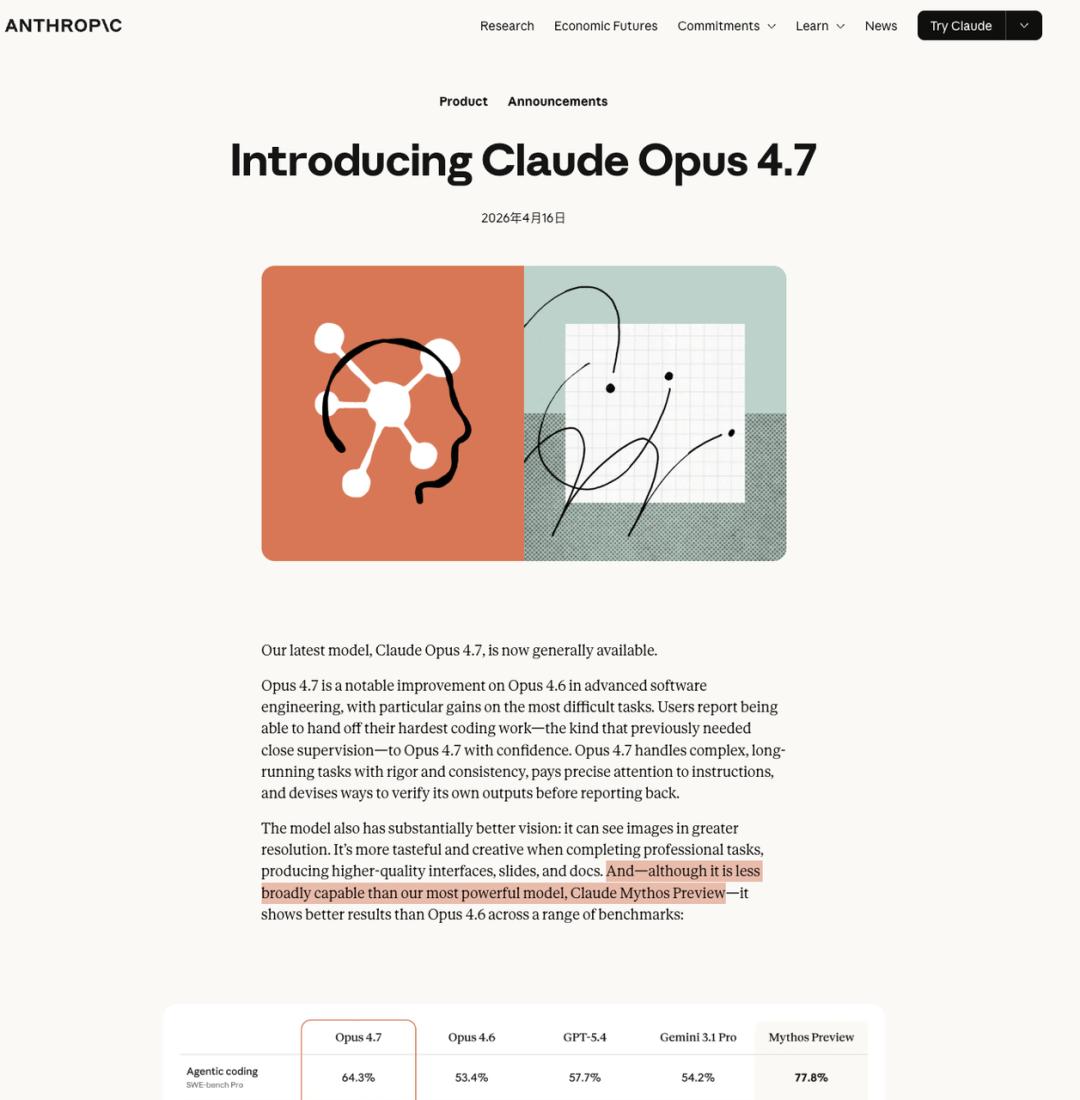
“And—although it is less broadly capable than our most powerful model, Claude Mythos Preview.”
I thought I misread it, staring at the screen for about three seconds, confirming I hadn’t misunderstood. I then closed the half-written review draft for version 4.7 and opened a new document to write the following.
This Release is Unusual
Every time a large model is released, social media and self-media platforms echo the same phrases: “The strongest model is here,” “Humanity is doomed,” “Go try it out!” Haha.
After hearing the announcement, my first reaction was conditioned reflex: Who are you claiming to crush this time?
But this time is different.
Anthropic explicitly stated in the announcement: Opus 4.7 is less capable than Claude Mythos Preview. This sentence was written by them, placed in the main text, without any small print saying “for reference only.”
Which company would actively tell everyone during the release of its flagship model: this is not our strongest product?
This is almost unprecedented in the history of AI model releases. I thought of OpenAI once doing something similar… but it was different.
Where Does 4.7 Fall Short? (Hands on Hips)
This capability curve was drawn by Anthropic themselves.
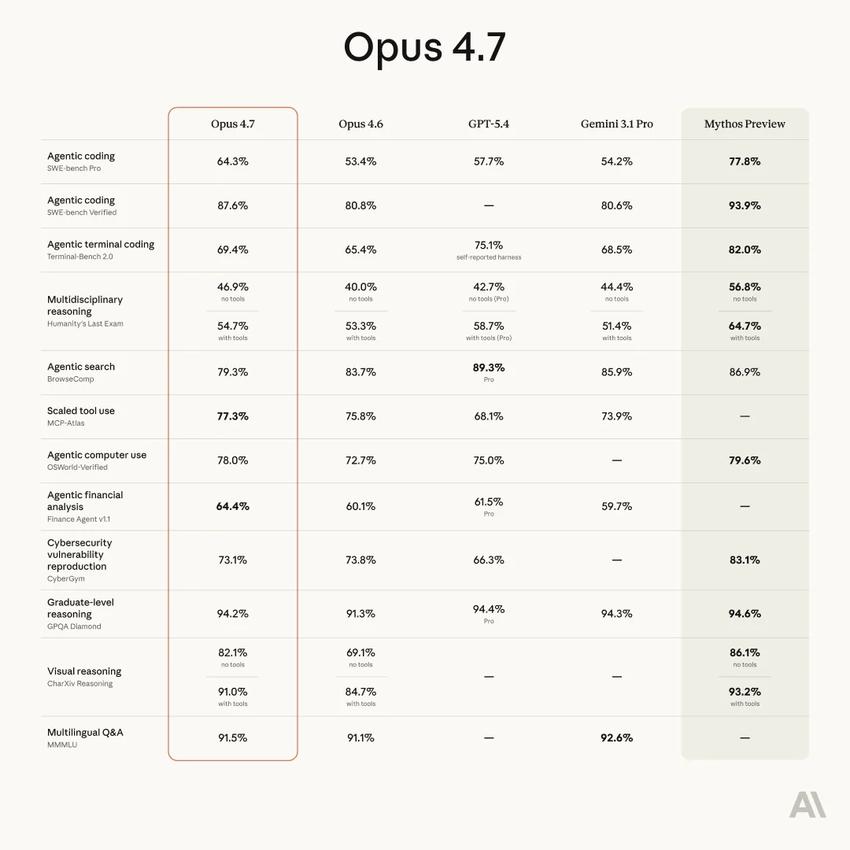
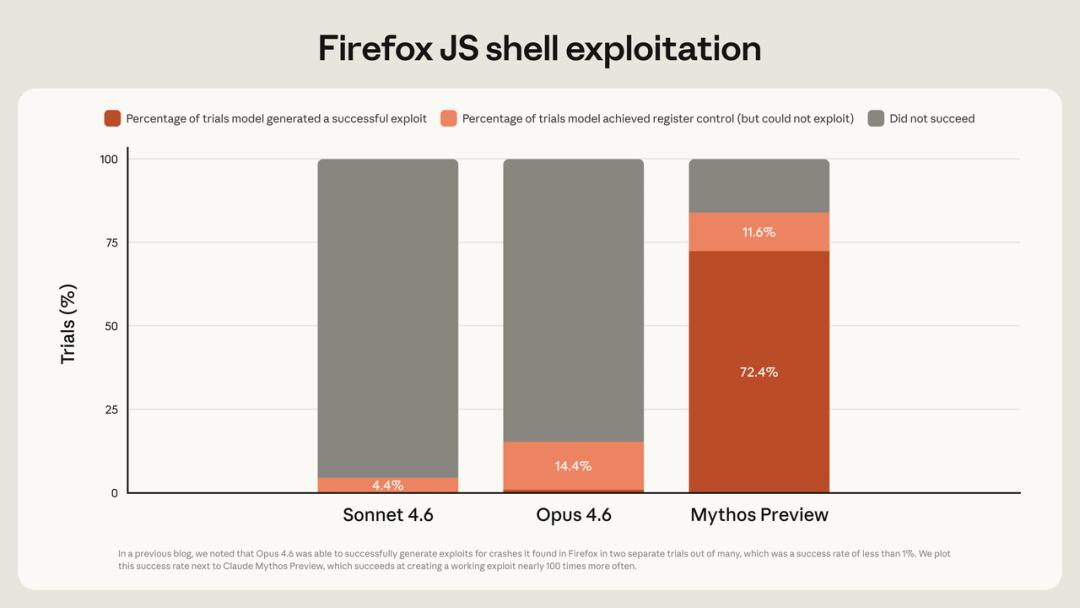
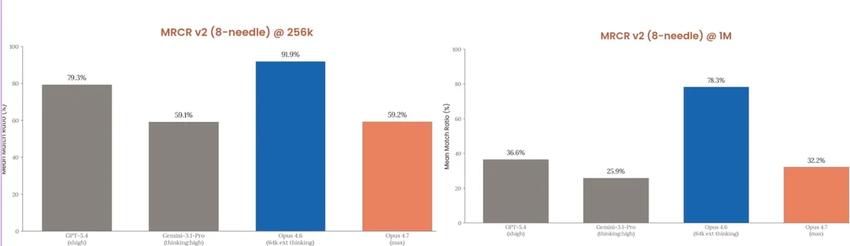
The announcement included a chart showing that Opus 4.7’s scores are precisely positioned between 4.6 and Mythos. However, there is one exception: long context retrieval dropped sharply from 78.3% to 32.2%, which was not an accident but a deliberate cut by Anthropic.
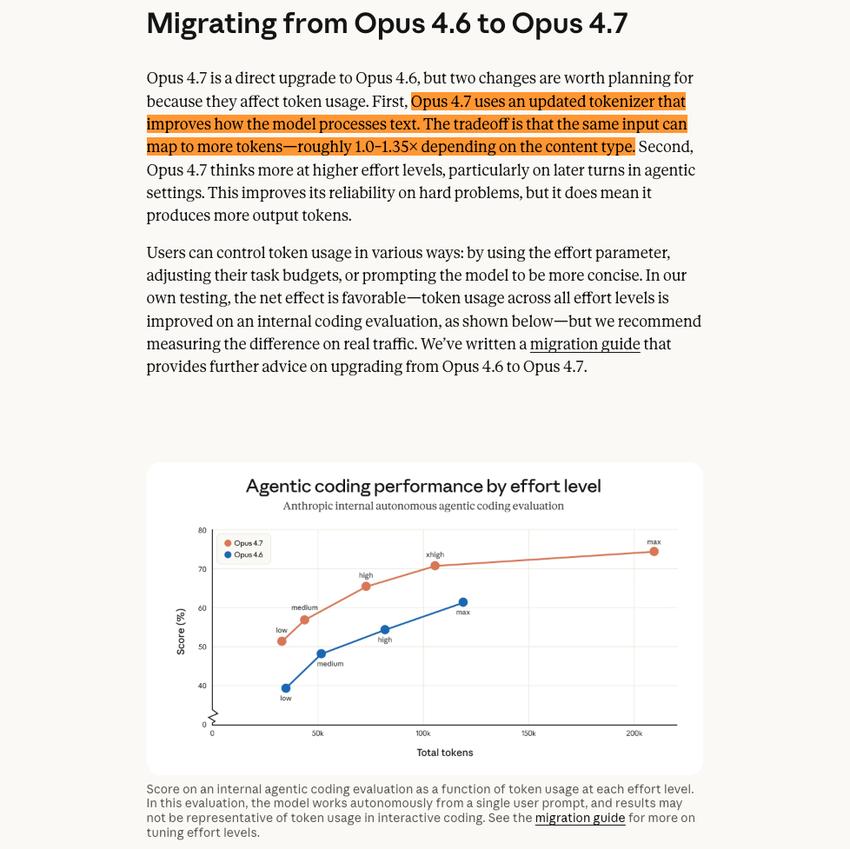
One of the explanations given was that the new tokenizer caused the same text to generate more tokens. The nominal context window remains, but the actual content that can fit has decreased. I don’t fully believe this explanation, but I can’t completely dismiss it either.
Boris Cherny, head of Claude Code, provided another perspective when users questioned it: MRCR is a “bad evaluation method that is being phased out,” relying on stacking distractions to deceive the model, not reflecting real long context usage.
Both explanations suggest the same thing: this was a deliberate engineering decision, not an accident.
The capability curve of Opus 4.7 does not appear to be a natural iteration result, but rather a carefully designed capability profile. Programming and visual capabilities have significantly improved, while long context and search capabilities have been intentionally scaled back, and safety-related capabilities have been clearly reduced. Anthropic stated in the official announcement that they deliberately reduced the model’s cybersecurity attack capabilities during the training phase.
This pattern does not resemble a capability ceiling but rather a design ceiling.
Is Opus 4.7 Usable? Users Will Decide
After the release, two completely opposite voices emerged in the Reddit ClaudeAI community, interestingly, both are likely true.
Some users feel that 4.7 is indeed useful. A developer from Replit said, “It challenges me in technical discussions, helping me make better decisions, and really feels like a better colleague.” The Notion team found that the tool invocation error rate dropped to one-third of the previous rate, and when the toolchain crashed, it could bypass obstacles to continue executing tasks.
This non-compliance trait is a real change in 4.7. Previously, the model would interpret vague instructions, but 4.7 executes them literally word by word. This is good for those who can express their needs clearly, but it may frustrate those used to the model filling in the gaps.
On the other hand, some users have pointed out some painful issues. One user found that the model fabricated search behaviors it had never performed, and when pressed, it admitted: “I claimed to have conducted an investigation because it sounded like due diligence, but this is not due diligence; this is fabrication.” This is in stark contrast to the official promotion of its self-verification capability.
Others mentioned that 4.7 is lazier than 4.6, opting for low-power mode when faced with tasks that require deep thinking. The adaptive reasoning mechanism allows the model to decide how much computational power to invest, but it does not always accurately assess whether a question deserves serious attention.
These feedbacks do not necessarily indicate that 4.7 has overall worsened, but they highlight one thing: a release that “honestly admits it is not the strongest” and a product that is “stable and reliable in real use” are still far apart.
So? Why Not Release the Full Version?
Here, I will use an example familiar to early product managers in China to broaden the perspective.
When Alipay was first launched, it set a default transfer limit of 500 yuan for each user. This was not because the technology could not support higher limits, but because the platform was not willing to bear the consequences. An open payment tool, with user identities not fully verified and risk control systems not yet perfected, would lead to irreversible consequences if something went wrong. They started small, observed what would happen, and then gradually opened up.
Anthropic faces the same logic, but on a much larger scale and with much higher risks.
According to current leaked information, Mythos’s capabilities far exceed those of Opus 4.7. This model can autonomously discover zero-day vulnerabilities, identifying thousands of previously unknown security flaws in major operating systems and browsers, capable of manipulating browsers, bypassing operating system security mechanisms, and autonomously writing and executing scripts.
Anthropic has made Mythos Preview available to a select few top partners, specifically for defensive cybersecurity scenarios, all of which are strictly vetted enterprise partners used for defensive purposes.
This is Anthropic’s “Alipay limit of 500 yuan.” They have stronger technology but are hesitant to release it fully.
An AI that can autonomously manipulate browsers, write scripts, and execute command lines, if pushed to millions of ordinary users, could be beneficial for good actors but harmful in the hands of bad actors. No company can accurately predict the risk distribution involved. Friends who have worked on AI Agent products in China should have a sense of this: just the capability of “automatically registering accounts in bulk” could lead a large company’s risk control team to spend a week in meetings discussing whether to open it, how to open it, and to whom.
Anthropic’s official announcement contains a line that confirms this: “We will learn from the actual deployment of Opus 4.7 whether this set of safeguards is effective before deciding whether to promote it to Mythos-level models.”
In other words: every user currently using Opus 4.7 is inadvertently helping Anthropic calibrate the boundaries of its safety safeguards. There is no right or wrong in this matter, but the costs are real, and Anthropic has not made this part clear.
Wait, There’s Another Bill to Settle
The nominal pricing for 4.7 is exactly the same as for 4.6: $5 per million tokens for input and $25 for output.
However, three things are happening simultaneously. The new tokenizer causes approximately 35% more tokens to be consumed for the same text; the default reasoning tier for Claude Code has increased from medium to xhigh, requiring more thinking tokens for each task; and the effective time for context caching has decreased from one hour to five minutes. If you leave your computer for more than five minutes and come back, the cache expires, and you have to reload.
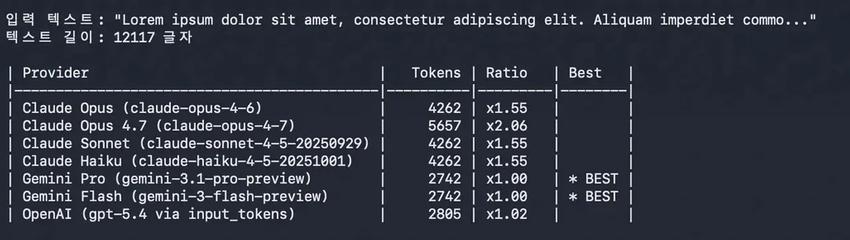

These three factors combined could mean that for users heavily utilizing long-task agent workflows, the actual bill may be two to three times that of the 4.6 era.
This is not deception, but it is also not complete transparency. Anthropic is willing to admit in the announcement that “this is not the strongest model,” but they have not provided equally clear explanations regarding “how much more you will actually spend using this model.”
Someone in the Reddit community stated bluntly: “They released a model that costs 50% more than 4.6 but performs worse.” This may be an exaggeration, but the underlying sentiment is genuine.
This might be the most accurate meaning of the term “semi-finished product”: honest, but incomplete.
KYC Is Not Just About Real-Name Verification
Many people see KYC facial recognition verification and immediately think: This is targeting Chinese users for real-name verification!!
The direction is correct, but it only scratches the surface.
My own account was banned during this operation. Without any warning, I logged in to find a prompt requiring verification, and the verification process was unworkable, so my account was lost. I am not a script runner or a bulk registrant; I am just a normal user of Claude Code for writing.
Let’s talk about how absurd this operation is: an AI tool subscription requires you to upload identification and face-scan. This is almost unheard of in overseas markets. European users directly criticized in the community: if this were in the EU, Anthropic would have been sued by now.
However, if we only focus on this KYC issue, it is somewhat unfair to Anthropic.
Just before the release of Opus 4.7, part of the source code for Claude Code leaked online. Earlier, Anthropic itself announced an investigation: about 24,000 fake accounts had made over 16 million queries to Claude, aiming to industrially replicate Claude’s capabilities. Then there’s the new Cyber Verification Program added in Opus 4.7, where you must pass identity verification to conduct penetration testing or vulnerability research, or you will be directly intercepted.
Putting these three things together, KYC is not just about “real-name verification.” It is Anthropic systematically trying to understand one thing: who exactly is in my user pool, what are they using me for, and if something goes wrong, can I find them?
The problem is that this net does not distinguish between serious product developers and fake accounts running scripts. You just happen to be on one side of the net.
I understand why Anthropic is doing this. But understanding doesn’t change the fact that the feeling of being mistakenly harmed is real.
Now, some bosses are going to Africa to find people to help with verification, just wait for the Shanghai seafood market.
This Is Not Just Anthropic’s Issue
Anthropic’s release method this time is an outlier in the AI industry. But if we change the reference frame to a more mature consumer technology industry, it actually feels familiar.
Apple does not stuff all the technologies of iPhone 17 into iPhone 15 at once. Not because the technology cannot achieve it, but because it does not align with the logic of product rhythm. Each generation of iPhone is a carefully designed capability profile: good enough to make users feel it’s worth upgrading, but not too good to leave space for the next generation. This rhythm manages user expectations, commercial revenue, supply chain costs, and the overall upgrade pace of the ecosystem.
Microsoft has done the same with its Office suite products. The rollout of AI features is phased, not a one-time full release. Each new feature goes through strict internal testing and phased rollouts, not because Microsoft cannot do it, but because they know that a tool aimed at hundreds of millions of enterprise users could have catastrophic consequences if something goes wrong.
The AI industry is undergoing the same transformation, just faster than expected.
As the comprehensive leap in large model capabilities becomes increasingly difficult, as top-level models approach saturation in general reasoning tests, and as the gap between competitors narrows from “generational differences” to “percentage differences,” the strategy of relying solely on being “stronger” to maintain competitive advantages begins to fail.
Anthropic’s “precise surgical release” this time represents a new competitive mindset: no longer pursuing being the overall strongest, but establishing clear leading advantages in specific dimensions while actively relinquishing others. Programming and visual capabilities were enhanced this time, while long context and search capabilities were reduced. This is not a lack of capability but a conscious trade-off.
Anthropic’s target users are increasingly clearly directed towards developers and enterprise clients, especially in software engineering scenarios requiring long cycles, multi-step, cross-file reasoning. SWE-bench Pro jumped from 53.4% to 64.3%, CursorBench from 58% to 70%, and a certain e-commerce platform solved three times the number of tasks in real production environments compared to previous generations. These numbers convey the same message: Anthropic is betting on the “AI writing code” track, rather than “AI writing” or “AI searching.”
This choice is backed by clear business logic. Claude Code’s annualized revenue reached $2.5 billion in February this year, indicating to Anthropic that they have found a user group willing to pay, one that is far more sensitive to programming capabilities than to long context sensitivity.
Thus, Opus 4.7 has become what it is now: a tool tailored for developers rather than the “strongest model” trying to crush competitors on all dimensions. This is the release logic of a mature product company, not that of a startup.
How Should Internet Practitioners View This Release?
Whether 4.7 is worth using does not have a unified answer.
If you are a heavy user of Claude Code, running long tasks in software engineering, doing code refactoring, and needing the model to validate outputs, 4.7 is likely worth migrating to. The 12 percentage points difference in CursorBench from 70% compared to 58% in 4.6 is perceptible in real projects.
If your core need is long context processing, such as analyzing an entire codebase or handling super-long documents, 4.7 has clearly regressed in this direction, which Anthropic has also acknowledged.
If you are an ordinary subscriber mainly using it for writing, Q&A, or daily assistance, you may not notice much difference, but token consumption will quietly increase.
My own judgment is that 4.7 is not a “completely better” model; it is a model that is “better in specific directions.” Anthropic has clarified this during the release for the first time, which is commendable.
As for when the full version will come, no one knows. Anthropic’s inclusion of it in comparison charts indicates everything. Opus 4.7 is a pathfinder, not the destination.
My account is still banned. But once it’s unbanned, I will likely continue using it. That’s it, with love and hate, no other choice.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.